
Los Columnstore Indexes presenta una nueva estructura almacenando columnas en lugar de filas, y está diseñado para acelerar el procesamiento de análisis de consultas y datos en un data-warehouse. Pero se debe tener en cuenta que los índices de almacén en columnas aunque son eficaces, no son un vaso de agua en el desierto, ya que hay una serie de limitaciones en ellos. Cuando se usa apropiadamente, pueden reducir entradas y salidas de disco y utilizar la memoria de manera más eficiente.
Desde SQL Server 2012, se puede definir Columnstore Indexes en las tablas de base de datos. Un Columnstore Indexes almacena los datos en un formato por columnas, a diferencia de las estructuras de árbol B tradicionales que se utilizan para los índices de almacenamiento de filas agrupados y no agrupados, que almacenan los datos de modo de fila (en filas).
Un índice de columnas organiza los datos de las columnas individuales que se unen entre sí para formar el índice. Esta estructura puede ofrecer mejoras de rendimiento significativas para las consultas que resumen grandes cantidades de datos, como los utilizados normalmente para la inteligencia empresarial (BI) y almacenamiento de datos.
Estructura del Columnstore Index
Columnstore indexes se basan en xVelocity (anteriormente conocido como VertiPaq), una avanzada tecnología de almacenamiento y compresión que se originó con PowerPivot y Analysis Services, pero se ha adaptado a las bases de datos de SQL Server 2012. En el corazón de este modelo es la estructura columnar que agrupa los datos por columnas en lugar de filas. Para entender mejor cómo funciona esta estructura, vamos a ver una tabla sencilla (AUTOTYPE) que almacena los datos relacionados con el automóvil. El siguiente código T-SQL muestra la definición de la tabla:CREATE TABLE TipoAuto ( AutoId INT NOT NULL,
Marca VARCHAR(20) NOT NULL,
Modelo VARCHAR(20) NOT NULL,
Color VARCHAR(15) NOT NULL,
AñoModelo SMALLINT NOT NULL ,
CONSTRAINT PK_TipoAuto PRIMARY KEY CLUSTERED (AutoId) )
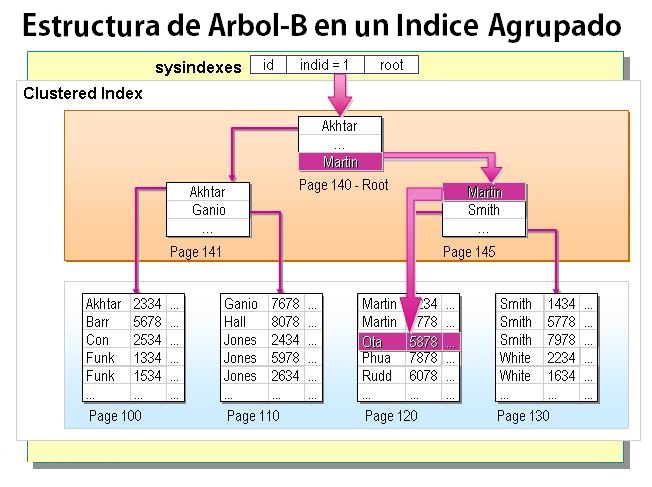
Aquí no hay nada elaborado, sólo algunas columnas configuradas con los tipos básicos. Pero tenga en cuenta que la columna de la AutoID se configura como la clave principal e índice agrupado. Como es típico de un índice agrupado, los datos se ordenan físicamente en el disco en páginas de datos, como se ilustra en la Imagen de abajo.
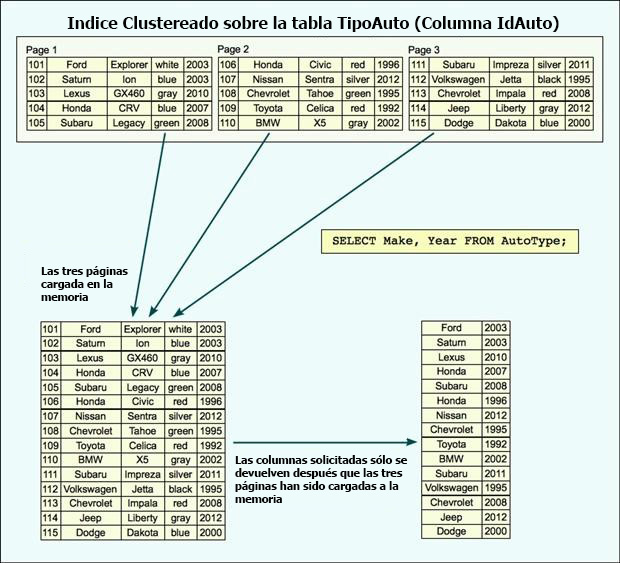
En este caso, los datos se dividen en tres páginas, con cada uno conteniendo cinco filas. Esto, por supuesto es un ejemplo en un escenario muy poco probable, ya que cada página normalmente contener muchos más datos, pero para fines de demostración, esta configuración debería funcionar bien. El punto importante a destacar es que cada fila se almacena en una página en su totalidad. Ahora supongamos que ejecute la siguiente consulta en la tabla TIPOAUTO:
SELECT Marca, AñoModelo FROM TipoAuto;
Cuando el motor de base de datos procesa la consulta, recupera las tres páginas de datos en la memoria, buscará toda la tabla a pesar de que la mayor parte de las columnas no son necesarios. En otras palabras, desperdiciara recursos de entrada y salida y memoria para recuperar datos innecesarios. Ahora veamos cuando se crea un columnstore index en la tabla. En este caso, hemos incluido todas las columnas en el índice, aunque en realidad probablemente habría que incluir soló algunas columnas. Cualesquiera que sean las columnas que incluimos, se almacenan en el índice, en algo similar a la imagen abajo. Como se puede ver, los datos ya no se almacenan por fila.
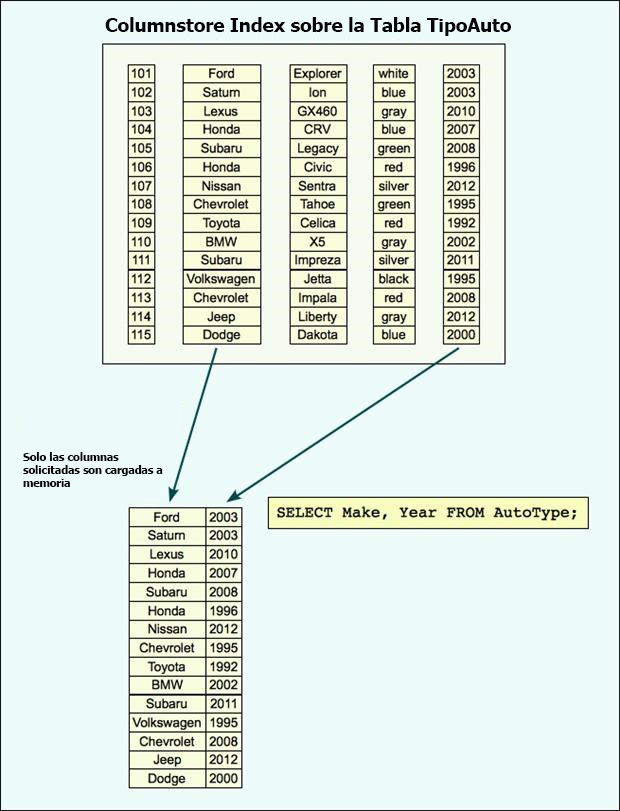
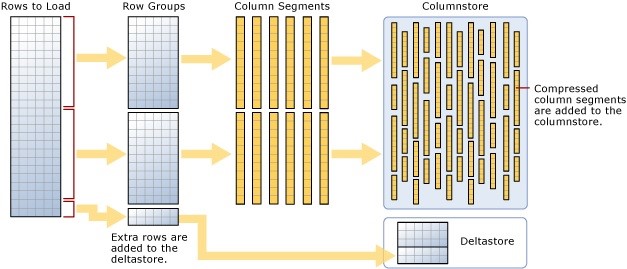
En el índice de columnas mostrado en la figura, cada columna es su propio segmento. Un segmento puede contener valores de una columna única, que permite que los datos de cada columna para acceder de forma independiente. Sin embargo, una columna puede abarcar varios segmentos, y cada segmento puede ser formado por varias páginas de datos. Los datos se transfieren desde el disco a la memoria por segmento, no por página. Un segmento es un objeto grande altamente comprimido (LOB) que pueden contener hasta un millón de filas. Los datos dentro del segmento de cada columna coinciden fila por fila para que las filas siempre se pueden montar correctamente. Por ejemplo, la segunda fila en cada segmento en la Imagen de arriba, apuntan al mismo automovil: el azul 2003 Saturn Ion con un IdAuto de 102. Las filas coincidentes en todos los segmentos forman un grupo de filas. Pronto nos ocuparemos de los grupos de filas en más detalle en breve, pero primero volvamos a la declaración SELECT. Si corremos la instrucción de nuevo, después de la creación de nuestro columnstore index, el procesador de consultas usará el columnstore index, en lugar del índice agrupado. Como resultado, sólo los segmentos asociados con el año, marca y el Modelo serán sacados en la memoria, lo que reduce los recursos necesarios para procesar la consulta. Esto es especialmente importante en las entradas y salidas de disco. A pesar de que hemos visto grandes saltos en el procesamiento y capacidad de memoria, El disco duro y sus entradas y salidas sigue siendo el eslabón más débil de una consulta, pero la estructura de columnas puede ayudar a reducir las E/S de manera significativa. Por supuesto, los datos de una columna no cabrán siempre en un solo segmento, dada la limitación de un millón de fila. En tales casos, múltiples segmentos se crean para cada columna y se agrupan en múltiples grupos de filas, una para cada conjunto de segmentos. Cuando un columnstore index se divide en varios grupos o segmentos de filas, cada grupo de filas contiene un conjunto de filas completas. Por ejemplo, la siguiente figura muestra el índice de almacén de columnas ahora dividida en tres grupos de filas. Cada grupo de filas contiene segmentos para cada columna, y juntos los segmentos forman el conjunto completo de filas.
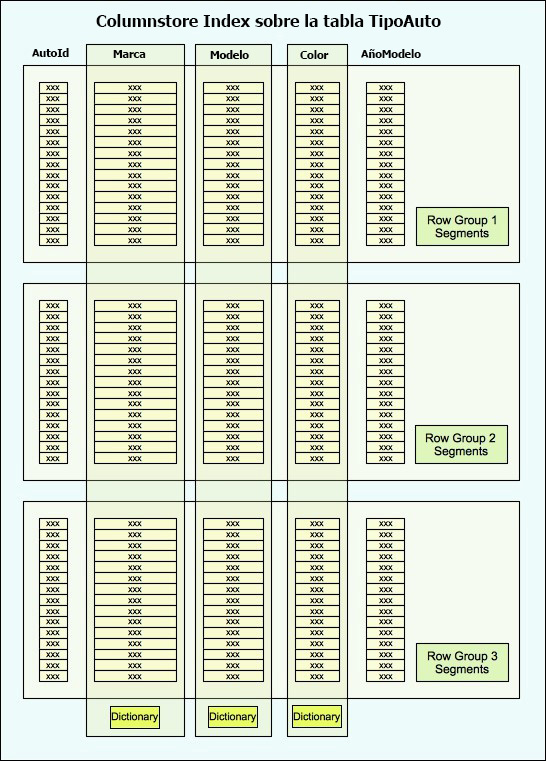
Nótese que la figura de arriba muestra también varios diccionarios, cada uno asociado con una columna específica. Un diccionario codifica los valores de una columna configurada con un tipo de datos de cadena o, en algunos casos, un tipo no-string si la columna contiene unos valores distintos. Aunque no todas las columnas utilizan diccionarios, todas las columnas de cadenas de texto sí. Cuando se utiliza un diccionario, que almacena valores de datos reales de la columna, y los valores numéricos de referencia se insertan en los segmentos en lugar de esos valores. Esto puede ofrecer una gran ventaja en el rendimiento para las columnas que contienen muchos valores repetidos, pero puede tener un impacto negativo sobre columnas con una gran cantidad de valores únicos. Aun así, una columna de cadena siempre utiliza un diccionario primario e incluso podría utilizar un diccionario secundario.
Funcionamiento del Columnstore Index
Como se señaló anteriormente, una de las mayores ventajas que ofrece un columnstore index es la reducción de E/S, que puede tener un impacto directo en el rendimiento de las consultas. Sólo para dar una idea de esto, veamos un ejemplo sencillo. La siguiente instrucción SELECT recupera los datos de la tabla FactResellerSales en la base de datos de ejemplo AdventureWorksDW2012 que puede descargarse en https://msftdbprodsamples.codeplex.com/downloads/get/165405:SELECT ProductKeyM, UnitPrice, CustomerPONumber, OrderDate FROM FactResellerSales;
La definición de la tabla incluye una clave principal compuesta definida en las columnas SalesOrderNumber y SalesOrderLineNumber, que forman la base del índice agrupado de la tabla. Como resultado, cuando se ejecuta la consulta, el procesador de consultas realiza un recorrido de índice agrupado.
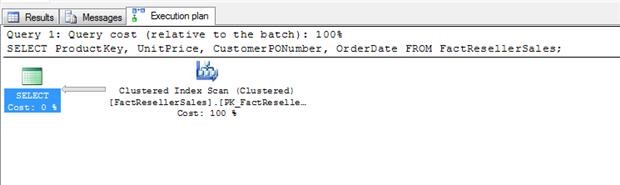
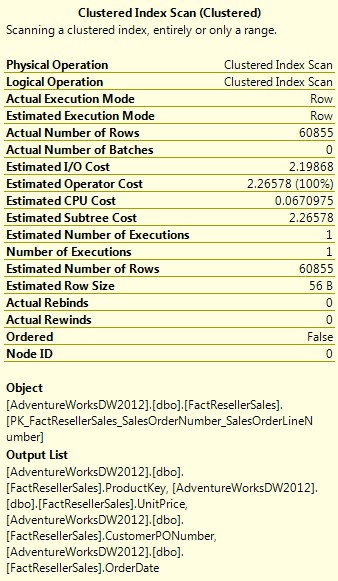
No hay nada demasiado sorprendente aquí. Puesto que la tabla contiene sólo 60.855 filas, la consulta se procesa de forma casi instantánea. Aún así, vale la pena echar un vistazo rápido a los detalles del plan de ejecución, que se muestra en la siguiente figura. En particular se nota el “Estimated I/O Cost” que es de 2,19868. Observe que esto representa una parte significativa de los costos totales de los operadores (Estimated Operator Cost) de 2,26578. El resto de los costos del operador va a la CPU, que está en el puesto solamente 0.0670975.
CREATE NONCLUSTERED COLUMNSTORE INDEX CSI_FactResellerSales ON dbo.FactResellerSales (ProductKey, UnitPrice, CustomerPONumber, OrderDate);
Crear de un ColumnStore Index es tan simple como crear cualquier tipo de índice no agrupado. Una vez que creamos el columnStore Index, podemos volver a ejecutar nuestra consulta. La instrucción SELECT una vez más vuelve nuestras filas instantáneamente, por el pequeño grupo de datos que es, pero produce un plan de ejecución diferente, veamos para esto la siguiente figura.
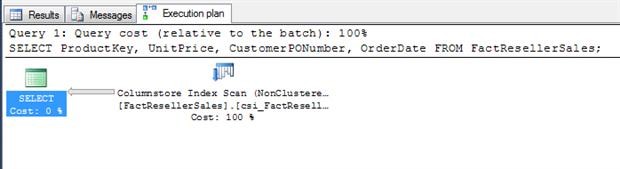
Como se puede ver, esta vez el procesador de consultas realiza un recorrido del Columstore index, en lugar de un recorrido de índice agrupado. Y si revisamos los detalles del plan de ejecución, que sigue abajo, revela una imagen muy diferente de E/S.
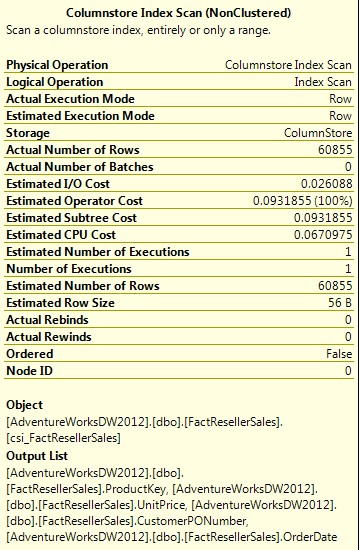
Nótese en primer lugar que los costos de la CPU son los mismos que para el índice agrupado: 0,0670975. Sin embargo, nuestro operador “Estimated Operator Cost” esta vez es sólo es 0.0931855, en comparación con 2,26578 para el índice agrupado. Esto se debe a nuestro costo de E/S es ahora sólo 0,026088, en lugar del 2,19868 devueltos por la consulta utilizando el índice agrupado. Este ejemplo es, sin duda, es sencillo, pero demuestra la naturaleza como el índice columnar puede reducir los costos de E/S en sus consultas. Sin embargo, la estructura del índice columnar no es el único aspecto que da lugar a mejoras del rendimiento. La compresión también desempeña un papel integral. Ya que los datos en un índice de columnas se agrupan por columnas, en lugar de por filas, los datos se pueden comprimir de manera más eficiente que con índices almacenados en filas. Los datos leídos desde una sola columna son más homogéneos que los datos leídos de filas, y cuanto más similares sean los datos, más fácil de comprimir. Además, si se le añade un bajo número de valores distintos y el uso de diccionarios, solo hay ventajas. La tecnología xVelocity también trae algoritmos de compresión sofisticados que pueden sacar el máximo provecho de la naturaleza columnar de los índices. Y la manera más eficaz de comprimir los datos, ya que más datos cabrán en una sola página y cuantos más datos se puede cargar en la memoria, menos costos de entradas y salidas de disco. Si se tiene en cuenta la naturaleza de las cargas de trabajo de BI, que a menudo implican la agregación de grandes conjuntos de datos, se puede ver la clara ventaja de la estructura de columnas. La necesidad de que el aumento de la potencia de la CPU que requiere dicha agregación puede ser compensado por los ahorros de E / S, lo que ayuda a mejorar el rendimiento de las consultas gigantescas.
Mejoras en SQL Server 2016

No hay comentarios:
Publicar un comentario