
Con la ferviente creencia que es vital en nuestro día a día el conocimiento informático hace más eficiente a las personas y sus procesos corporativos, se creó este blog que es un aporte a la comunidad hispanoamericana, que busca material técnico y practico en español.
lunes, 7 de diciembre de 2020
¿Para que sirve Power Query Editor en PowerBi Desktop?
En este video hacemos una introducción a el Power Query Editor de Power BI Desktop y aprendemos a manejar parametros.
sábado, 5 de diciembre de 2020
¿De qué se trata Power BI Desktop?
Prepara tableros para mostrar la situación de tu empresa de manera fácil.
Power BI Desktop te permite crear los mejores tableros de control para tu negocio o proyecto en poco tiempo y compartirlo con otras personas y dispositivos.
viernes, 13 de noviembre de 2020
Instalación y Configuración del Reporting Services
Reporting Services (SSRS) del SQL Server proporciona un conjunto de herramientas y servicios locales que crean, implementan y administran informes móviles y paginados.
lunes, 2 de noviembre de 2020
¿Cómo funciona la función YEAR() en el SQL Server?
Hay muchas funciones diferentes relacionadas con la fecha y hora disponibles en SQL Server, como DAY, MONTH, YEAR, DATEDIFF, etc. .Por ejemplo, la función YEAR se puede utilizar para extraer el valor del año de una fecha, como en el siguiente ejemplo:
DECLARE @TRANSACTION_DATE DATETIME
SET @TRANSACTION_DATE=’2020-11-02 15:20:30′
SELECT YEAR(@TRANSACTION_DATE) AS TRANSACTION_YEAR
Pero ahora surge algo interesante, que pasa si ejecutamos la siguiente sentencia:
SELECT YEAR(555660/20) AS YEAR_VALUE
¿Por qué el resultado es el siguiente?

Resulta que SQL Server es compatible con el sistema de fechas que parten de1900, es decir cuando ingresa una fecha, la fecha se convierte en un número de serie que representa el número de días transcurridos desde el 1 de enero de 1900.
Entonces, si estamos haciendo la consulta SELECT YEAR(555660/20), estamos escribiendo SELECT YEAR(27783), sin embargo, el 27783 los toma como días a partir del 1 de enero de 1900, lo que equivale a la fecha 25/01/1976, y si a esta fecha se le extrae el año queda solo 1976 de allí el porqué del resultado.
jueves, 15 de octubre de 2020
Demostración del proceso de Autenticación en el SQL server.
En este laboratorio vemos el proceso de autenticación hacia el SQL Server usando una cuenta de dominio de Active Directory.Siguenos en nuestras redes sociales https://www.youtube.com/visoalgt https://twitter.com/victhorcardenas https://www.instagram.com/vh_cardenas/
sábado, 3 de octubre de 2020
Cambiar nombre del Servidor de SQL Server
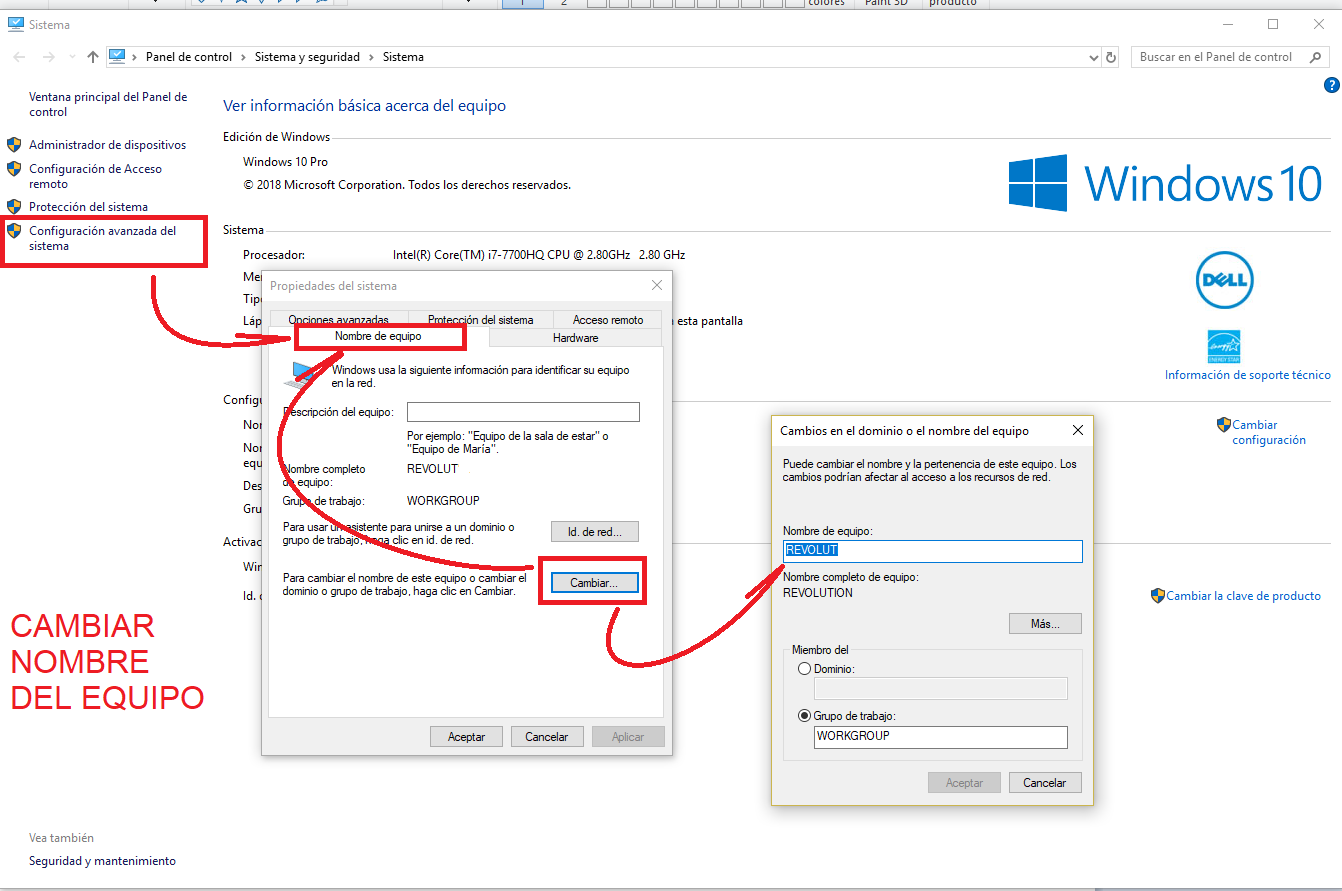
Recientemente tuve problemas al montar una replicación de SQL Server donde se había cambiado el nombre de los servidores pero no se había actualizado las instancias de SQL Server lo que impedía se realizara la replicación, esto da origen al siguiente post.
Un problema bastante común en SQL Server es cambiar el nombre del equipo o servidor donde está instalado nuestro SQL, esto provoca varios conflictos en nuestra instancia de SQL, no trabajan los asistentes, deja de funcionar la replicación entre servidores, hay varios problemas porque no podemos hacer referencia al nombre de la instancia porque esta ya no tiene el nombre correcto.
La explicación es s que durante la instalación de SQL Server se graba en la base de datos del sistema, master, el nombre del servidor. Cuando cambiamos el nombre del servidor, estos datos no se actualizan de forma automática en la base de datos master, con lo que la información se desfasa
Este nombre lo podemos consultar a través de la variable global @@SERVERNAME.
Luego de cambiar nombre del servidor entonces debemos en nuestro SQL Management Studio cambiar el nombre de nuestra instancia, para esto borramos el nombre del servidor anterior, nombre obtenido con consultar la variable @@SERVERNAME con un simple SELECT @@SERVERNAME, y luego agregamos nuevamente nuestro servidor con el nombre actual, el script es el siguiente:
Select @@SERVERgo
sp_dropserver ‘old_name’
go
sp_addserver ‘new_name’, ‘local’go
El nombre actual del servidor se obtiene de escribir en la linea de comandos de Windows la instrucción Hostname
Si se trata de una instancia con nombre las instrucciones deberían de ser:
sp_dropserver <old_name\instancename>; go
sp_addserver <new_name\instancename>, local; go
viernes, 10 de julio de 2020
Tipos de dato espaciales de SQL Server
SQL Server no tiene ningún problema en guardar información relacionada con coordenadas, para obtener posicionamientos es decir ubicaciones o calculo de áreas geográficas o geométricas, para esto se vale de dos tipos de dato, que son geometry y geography .
Hay que tener en cuenta que en la industria, los datos espaciales vienen en muchas formas, contamos con sistemas basados en ráster que representan los datos como una serie de píxeles o puntos. y también tenemos los sistemas basados en vectores que representan formas como una serie de pequeños segmentos de línea. El soporte espacial para SQL Server se basa en datos vectoriales.
También hay sistemas que se basan en la tecnología 2-D, 3-D y 4-D. SQL Server actualmente admite aplicaciones 2-D. Puede almacenar y recuperar información tridimensional, pero no la utiliza durante la realización de cálculos.
SQL Server admite dos tipos de datos espaciales:
El tipo de datos geometry que admite datos planos o euclidianos (tierra plana) y se ajusta a las características simples del Open Geospatial Consortium (OGC) para la especificación SQL versión 1.1.0 y cumple con SQL MM (estándar ISO).
Además, SQL Server admite el tipo de datos de geography , que almacena datos elipsoidales (tierra redonda), como las coordenadas de latitud y longitud del GPS.
Ambos tipos de datos se implementan como tipos de datos .NET Common Language Runtime (CLR) en SQL Server, es decir bajo un asembly.
Los tipos de datos de geometry y geography admiten dieciséis objetos de datos espaciales, o tipos de instancia. Sin embargo, solo once de estos tipos de instancias son instanciables ; puede crear y trabajar con estas instancias (o instanciarlas) en una base de datos. Estos casos se derivan ciertas propiedades de sus tipos de datos de los padres que los distinguen como Puntos , cadenas lineales, circularStrings , CompoundCurves , polígonos , CurvePolygons o como múltiples geometría o geografía instancias en un GeometryCollection .
El tipo de geografía tiene un tipo de instancia adicional,FullGlobe
Creemos algunas variables de tipo espacial como ejemplo :
–Empecemos por consultar los sistemas de referencias con los que cuenta el sql server
Use tempdb;
go
Select * from sys.spatial_reference_systems
go
Select * from sys.spatial_reference_systems
where spatial_reference_id=4326
go
SELECT DISTINCT unit_of_measure, unit_conversion_factor
FROM sys.spatial_reference_systems;
GO
—Dibujar una forma usando geometría
Declare @shape geometry;
Set @shape= geometry::STGeomFromText(‘POLYGON((10 10, 25 15, 35 15, 40 10, 10 10))’,0);
Select @shape
go
–Dibujar un Circulo
DECLARE @G geometry = ‘CIRCULARSTRING(1 1, 2 2, 3 1, 2 0, 1 1)’
Select @G
—Dibujar dos forma usando geometría
Declare @shape1 geometry;
Declare @shape2 geometry;
Set @shape1= geometry::STGeomFromText(‘POLYGON((10 10, 25 15, 35 15, 40 10, 10 10))’,0);
Set @shape2= geometry::STGeomFromText(‘POLYGON((10 10, 25 5, 35 5, 40 10, 10 10))’,0);
Select @shape1
Union all
Select @shape2
go
—Dibujar la dos formas juntas
Declare @shape1 geometry;
Declare @shape2 geometry;
Set @shape1= geometry::STGeomFromText(‘POLYGON((10 10, 25 15, 35 15, 40 10, 10 10))’,0);
Set @shape2= geometry::STGeomFromText(‘POLYGON((10 10, 25 5, 35 5, 40 10, 10 10))’,0);
Select @shape1.STUnion(@shape2)
–Dibujar un pentágono
DECLARE @Pentagon geography;
SET @Pentagon = geography::STPolyFromText(
‘POLYGON(( -77.0532219483429 38.870863029297695,
-77.05468297004701 38.87304314667469,
-77.05788016319276 38.872800914712734,
-77.05849170684814 38.870219840133124,
-77.05556273460198 38.8690670969195,
-77.0532219483429 38.870863029297695),
( -77.05582022666931 38.8702866652523,
-77.0569360256195 38.870734733163644,
-77.05673214773439 38.87170668418343,
-77.0554769039154 38.871848684516294,
-77.05491900444031 38.87097997215688,
-77.05582022666931 38.8702866652523))’,
4326);
SELECT @Pentagon;
GO
–Medir la distancia entre los Angeles y Nueva York
Declare @NewYork geography;
Declare @LosAngeles geography;
Set @NewYork= geography::STGeomFromText(‘POINT(-74.0007339 40.726966)’, 4326);
Set @LosAngeles= geography::STGeomFromText(‘POINT(-118.24585 34.083375)’, 4326);
Select @NewYork.STDistance(@LosAngeles);
go
–Metodo Tostring
DECLARE @Point geometry;
SET @Point = geometry::STPointFromText(‘POINT(10 20 15 5)’, 0);
SELECT @Point.ToString()
GO
–Entrada GML
DECLARE @Point geography;
SET @Point = geography::GeomFromGml(‘ 12 50 ‘,4326);
SELECT @Point;
GO
–Medir la distancia entre los Guatemala y Nueva York
Declare @NewYork geography;
Declare @Guatemala geography;
Set @NewYork= geography::STGeomFromText(‘POINT(-74.0007339 40.726966)’, 4326);
Set @Guatemala= geography::STGeomFromText(‘POINT(-90.2307587 15.7834711)’, 4326);
Select @NewYork.STDistance(@Guatemala);
GO
–Agregar una columna a una tabla con el tipo de dato geográfico y agregarle datos
Use Northwind
GO
Alter table customers
add GeogCol1 geography;
go
Alter table customers
add GeogCol2 as GeogCol1.STAsText()
go
–– Es posible también asignar un índice espacial para este tipo de datos
Create spatial index SIndx_Customers on Customers (GeogCol1)
Update Customers Set GeogCol1 =
geography::STGeomFromText(‘LINESTRING(-122.360 47.656, -122.343 47.656 )’, 4326) where customerid=’ALFKI’
GO
–Consultemos el registro
Select * from customers where customerid=’ALFKI’
miércoles, 8 de julio de 2020
Notas sobre nuevas características de SQL Server 2019

Cuando un producto te gusta es emocionante ver la nueva versión y las mejoras que le han realizado.
SQL Server tiene un compromiso con el rendimiento, busca siempre mejorar el desempeño con respecto a las versiones anteriores y esto nuevamente lo logra en SQL server 2019, otro compromiso es también la inteligencia de datos sobre cualquier dato, este es uno de los principales aportes. que nos permite trabajar entre bases de datos relaciones y bases de datos de big data.
Podemos aplicar todo lo que sería inteligencia artificial y machine learning tanto con SQL server en modelos relacionales como apache spark en bases de datos nosql.
También se tiene soporte multiplataforma, con el clásico soporte para Windows, pero ahora con soporte para linux, docker y Kubernetes y diferentes lenguajes desde T-sql, java, php, python, ruby
Es una de las bases de datos de mejor rendimiento y más seguras en el mercado en los últimos años, SQL server es quien menos incidentes de seguridad tiene en la industria de base de datos y quizá la mejor herramienta en inteligencia de negocios, generando reportes y dashboard rápidamente.
Además se tiene que tener la cuenta el costo 10 veces más barato que Oracle y que el SQL Server incluye el motor de base de datos, el integration services, el Analysis Services, el reporting services, cosa que en otros gestores de base de datos se trabaja por módulos y cada modulo con un costo adicional.

Inteligencia de datos sobre todos los tipos de almacenamiento, se busca generar un hub de datos unificado en donde podemos tener consultas con diferentes plataformas o diferentes sistemas, también una administración centralizada a través de Azure data Studio, además que me permita hacer análisis de datos con aplicaciones inteligentes en bases de datos relacionales y no relacionales.

Entonces contamos con una ventaja competitiva con una plataforma de datos unificada,
conectándonos a datos en modelo relacional, nosql o sistemas de big data con hadoop, de estos datos de cualquier entorno podemos hacer inteligencia artificial o Machinne Learning usando Spark y SQL y todo a través de Azure Data Studio una herramienta multiplataforma.

Veamos un poco más a detalle cómo funciona la integración de SQL Server 2019 con big data, inteligencia de negocios, y Inteligencia artificial.
Primero: la virtualización de datos nos va permitir conectarnos a diferentes fuentes de datos sin necesidad de movernos o replicarlos, escalar todos los cálculos hacia esas tabla externas y tener un cache de los mismos.
Nosotros tenemos herramientas para hacer análisis y aplicaciones de negocios conectadas a nuestro motor de base de datos, tanto las herramientas de análisis como las aplicaciones de negocios van a invocar a un código Transact-sql seleccionando por ejemplo una tabla, esa tabla puede ser una tabla externa o local, si es externa puede residir en spark, en hdfs, en Oracle, y la comunicación a esas tablas externas va ser a través de un pools que controlará el procesamiento y un pool de datos para almacenar la información.
Segundo: En Big Data, tenemos a SQL Server con soporte para Spark y Data Lake, tenemos un portal de administración donde podemos manejar esql server, nuestro cluster de HDFS con seguridad integrada con active directory, con esto un sql server va a tener la capacidad de conectarse a un sistema de escalable y compartido de HDFS y también puede usarse compartido este hdfs con Spark
Tercero: Plataforma de Inteligencia Artificial completa primero con todo el concepto de contenedores administrados por API Rest y además usar dos plataformas para la fabricación de nuestros modelos con SQL Server Machinne Learning y spart Machinne Learning

Ahora enfoquémonos más hacia donde irán nuestras demostraciones, en lo que sería la medula espinal de nuestro SQL Server 2019, mejorando el rendimiento, la seguridad y la disponibilidad en la misión crítica.

Para todo lo que sería rendimiento en SQL server 2019 se tiene ahora Intelligent Query Processing, las herramientas anteriormente conocidas como Automatic Query Tunning cambiaron su nombre a Intelligent Query Processing para tenerlas todas dentro de una misma familia.
Esta familia de funciones de procesamiento inteligente de consultas (IQP) incluye funciones de amplio impacto que mejoran el rendimiento de las cargas de trabajo existentes con un mínimo esfuerzo de implementación para adoptar oor ejemplo Table Variable Deferred Compilation mejora el rendimiento hasta un 30%
También tenemos Bach Mode For Row Store que el principal beneficio de esta función es que mejora el rendimiento de las consultas analíticas y también reduce la utilización de la CPU de este tipo de consultas, antes esto solo se tenía para columnstore.
Aproximate QP es una nueva familia de características. Se agregaron para el manejo de grandes conjuntos de datos donde la capacidad de respuesta es más crítica que la precisión absoluta. Un ejemplo es calcular un COUNT (DISTINCT ()) en 10 mil millones de filas, para mostrar en una tabla. En este caso, la precisión absoluta no es importante, pero la capacidad de respuesta es crítica. La nueva función agregada APPROX_COUNT_DISTINCT devuelve el número aproximado de valores únicos no nulos en un grupo.
Memory Grant Feedback hace mejoras en los planes de ejecución en cache: El plan posterior a la ejecución de una consulta en SQL Server incluye la memoria mínima requerida necesaria para la ejecución y el tamaño de concesión de memoria ideal para que todas las filas quepan en la memoria. Tenemos problemas de rendimiento cuando los tamaños de concesión de memoria tienen un tamaño incorrecto. Obviamente si hay memoria asignada excesiva resultan en memoria desperdiciada y concurrencia reducida. Si la memoria es insuficiente causa desbordamiento costosos en el disco. Al abordar las cargas de trabajo repetitivas, la Memory Grant Feddback en modo por lotes recalcula la memoria real requerida para una consulta y luego actualiza el valor de concesión para el plan en caché. Cuando se ejecuta una instrucción de consulta idéntica, la consulta utiliza el tamaño de concesión de memoria revisado, mejorando el uso de la memoria.

Otra de las ventajas es mejoras en Always Encrypted con Secure Enclaves que permite hacer clasificación de datos y auditoria integrada directamente en el sql server.
Introducido en SQL Server 2016, Always Encrypted protege la confidencialidad de los datos confidenciales contra malware y usuarios no autorizados de SQL Server con altos privilegios . Los usuarios no autorizados con altos privilegios son DBA, administradores de computadoras, administradores de la nube o cualquier otra persona que tenga acceso legítimo a instancias de servidores, hardware, etc., pero que no deberían tener acceso a algunos o todos los datos reales.
Sin las mejoras discutidas en este artículo, Always Encrypted protege los datos cifrándolos en el lado del cliente y nunca permitiendo que los datos o las claves criptográficas correspondientes aparezcan en texto sin formato dentro del motor de SQL Server. Como resultado, la funcionalidad en columnas cifradas dentro de la base de datos está severamente restringida. Las únicas operaciones que SQL Server puede realizar en datos cifrados son las comparaciones de igualdad (solo disponibles con cifrado determinista). Todas las demás operaciones, incluidas las operaciones criptográficas (cifrado de datos inicial o rotación de clave) y / o cómputos ricos (por ejemplo, coincidencia de patrones) no son compatibles dentro de la base de datos. Los usuarios necesitan mover sus datos fuera de la base de datos para realizar estas operaciones en el lado del cliente.
Siempre cifrado con enclaves seguros resuelve estas limitaciones al permitir los cálculos en datos de texto sin formato dentro de un enclave seguro en el lado del servidor. Un enclave seguro es una región protegida de memoria dentro del proceso de SQL Server, y actúa como un entorno de ejecución confiable para procesar datos confidenciales dentro del motor de SQL Server. Un enclave seguro aparece como un cuadro negro para el resto del servidor SQL y otros procesos en la máquina de alojamiento. No hay forma de ver ningún dato o código dentro del enclave desde el exterior, incluso con un depurador.

Mejoras en el Always On, tengamos en cuenta cómo funciona Always On que permite tener una tolerancia de fallos mejorada, permite tener un servidor principal y nodos conectando a este replicando la data, si el nodo principal se cae inmediatamente pasa a pasivo y habilita uno de los nodos para continuar trabajando, pero mientras todo esta normal los nodos secundarios pueden ser leídos y utilizarse para conectar por ejemplo el reporting services, en sql server 2019 se pueden contar hasta con 6 nodos, uno de los problemas comunes era que el nodo principal soporta las operaciones del negocio con más actividad que los servidores secundarios fragmentaba más rápidos los índices, y entonces por ejemplo una tarea programada de mantenimiento de índices, levantaba un proceso sobre todos los nodos o servidores secundarios y esto levantaba bloqueos ocasionando los servidores sin poder realizar consultas, esto se mejora en sql server 2019 permitiendo contar con mantenimiento de índices en línea y también pudiéndose pausar y continuar, algo similar pasaba si implementábamos columnstoreindex.
Otro elemento importante es el soporte para cluster de Kubernetes que me permite contar con varios nodos que no necesariamente tienen que ser de Windows.

Contamos entonces con una plataforma de desarrollo moderna, más rápida, multiplataforma, para desarrollar en el entorno de nuestra predilección.

UTF-8: Las intercalaciones en SQL Server proporcionan reglas de clasificación, mayúsculas y minúsculas y propiedades de sensibilidad de acento para sus datos. Las intercalaciones que se usan con los tipos de datos de caracteres, como char y varchar , dictan la página de códigos y los caracteres correspondientes que se pueden representar para ese tipo de datos.
Alternativamente, comenzando con SQL Server 2019 (15.x), si se usa una intercalación habilitada para UTF-8 (_UTF8), los tipos de datos previamente no Unicode ( char y varchar ) se convierten en tipos de datos Unicode usando la codificación UTF-8. SQL Server 2019 (15.x) no cambia el comportamiento de los tipos de datos Unicode previamente existentes ( nchar , nvarchar y ntext ), que continúan utilizando la codificación UCS-2 o UTF-16.
Mejoras en el desarrollo, abarcando ahora más que solo Transact-sql, ahora podemos usar R, Python y java, en las bases de datos conectadas a graphos, mejoras en Machine Learning
Graphos es una base de datos de gráficos es un tipo de base de datos NoSQL que se basa en la teoría de gráficos. Las bases de datos de gráficos son ideales para almacenar datos que tienen relaciones complejas de muchos a muchos.
Si no conocen sobre una base de datos gráfica para tener una idea pensemos en el siguiente ejemplo: Las plataformas de redes sociales son uno de los mejores ejemplos de cómo funcionan las bases de datos gráficas. Considere un escenario donde a una persona le gusta un equipo de fútbol en particular. A un usuario también le pueden gustar uno o más estadios de fútbol. Alternativamente, un estadio de fútbol puede ser del agrado de múltiples usuarios. A los usuarios también les pueden gustar los estadios de fútbol y las ciudades. Un equipo de fútbol tiene un estadio local. Un estadio puede estar ubicado en una ciudad en particular y una ciudad puede tener múltiples estadios. Una base de datos gráfica es ideal para almacenar este tipo de información. Los usuarios, equipos, estadios y ciudades pueden implementarse como entidades o nodos. Por otro lado, los me gusta, el estadio local y las ciudades del estadio se pueden implementar como relaciones o bordes.

Como ya mencionamos el soporte multi-plataforma es muy importante agregando a las instancias en linux nuevas capacidades como la replicación, transacciones distribuidas y Machine Learning, además de soporte para LDAP, otra característica importante es el soporte en Always On Availability Groups para Kubernetes.

DBCC CLONEDATABASE
Genera un clon de una base de datos de solo esquema mediante DBCC CLONEDATABASE para investigar problemas de rendimiento relacionados con el optimizador de consultas.
El equipo de producto SQL ha realizado mejoras significativas en la funcionalidad, compatibilidad y rendimiento del índice de almacén de columnas durante SQL Server 2016 en función de los comentarios de los clientes.
sp_estimate_data_compression_savings
Cuando el equipo de SQL Server lanzó la compresión ROW y PAGE en SQL Server 2008, los clientes podían invocar sp_estimate_data_compression_savings procedimiento almacenado para estimar los ahorros de almacenamiento para la compresión ROW y PAGE. Tenga en cuenta que el ahorro de compresión fue solo una estimación basada en muestrear un subconjunto de filas de la tabla de origen y cargarlas en una tabla temporal y luego medir el tamaño de esta tabla temporal antes / después de la compresión.
Para la mayoría de los casos, la estimación del ahorro de compresión fue buena, excepto cuando los datos en la tabla de origen estaban sesgados. La mayoría de los clientes lo encontraron útil, ya que era una forma conveniente de ver los beneficios del almacenamiento. Sin embargo, como algunos de ustedes han descubierto, este procedimiento almacenado no se ha extendido para estimar los ahorros de almacenamiento del índice del almacén de columnas y que ahora aparecio en SQL Server 2019.
Una característica nueva y emocionante en SQL Server 2019 es sys.dm_db_page_info. Esta nueva función de administración dinámica (DMF) recupera la información de la página útil, como page_id, file_id, index_id, object_id, y page_type, que se puede utilizar para solucionar problemas y depurar problemas de rendimiento en SQL Server. Históricamente, la solución de problemas ha implicado el uso de la DBCC Page y el Dinamic Management Function no documentado sys.dm_db_page_allocations.
A diferencia de la página DBCC, que proporciona todo el contenido de una página, sys.dm_db_page_infosolo devuelve información de encabezado sobre las páginas. Afortunadamente, esto será suficiente para la mayoría de los escenarios de resolución de problemas y ajuste de rendimiento.

Azure data estudio, lanzado en septiembre 2018, multiplataforma disponible para mac, linux y Windows, es open source el codigo está disponible en Github,
Azure data estudio está enfocado a personas que pasan más tiempo desarrollando código, o personas que necesiten administrar sql server desde otro sistema operativo que no sea Windows,
SQL Management Studio está enfocado más a tareas administrativas, de seguridad, permite hacer reportes de Query store, sobre Windows,
Desde la versión 18.0 del SSMS se puede lanzar Azure Data Studio.
Características de Azue Data Studio:
- Es más liviano, corre más rápido
- Editor de código moderno, mejor intellisense
- Object explorer similar al SSMS
- Dashboards
- Se puede exportar el resultado de un query a csv, xml, json, excel
- notebooks, proyecto open source para phyton
- Tiene una terminal integrada
- Cuenta con Source Control git o github
- Actualizaciones mensuales
- Permite Creación de Snippets que sirve para auto-completar código frecuente


viernes, 3 de abril de 2020
Esquemas en el SQL Server
Comportamiento nuevo
La separación de propiedad de los esquemas tiene consecuencias importantes:
- La propiedad de los esquemas y de los elementos protegibles con ámbito de esquema es transferible.
- Es posible mover objetos entre esquemas.
- Un mismo esquema puede contener objetos que sean propiedad de varios usuarios de base de datos.
- Varios usuarios de base de datos pueden compartir un mismo esquema predeterminado.
- Se pueden administrar los permisos sobre esquemas y sobre elementos protegibles con mayor precisión que en las versiones anteriores.
- Cualquier entidad de seguridad de base de datos puede ser propietaria de un esquema. Esto incluye roles y roles de aplicación.
- Es posible eliminar un usuario de base de datos sin necesidad de eliminar objetos en un esquema correspondiente.
- El código escrito para las versiones anteriores de SQL Server puede producir resultados incorrectos si el código considera que los esquemas son equivalentes a los usuarios de base de datos.
- Las visas de catálogo diseñadas para versiones anteriores de SQL Server pueden devolver resultados incorrectos, incluidos sysobjects.
- Cuando se crea un objeto de base de datos, si especifica una entidad de seguridad de dominio válida (usuario o grupo) como la propietaria del objeto, la entidad de seguridad de dominio se agregará a la base de datos como esquema. Esa entidad de seguridad de dominio será la propietaria del nuevo esquema.
Para crear un esquema mediante SQL Server Management Studio
- En SQL Server Management Studio, abra el Explorador de objetos y expanda la carpeta Bases de datos.
- Expanda la base de datos en la que se va a crear el esquema de la misma.
- Haga clic con el botón secundario en la carpeta Seguridad, seleccione Nuevo y, a continuación, haga clic en Esquema.
- En la página General, escriba un nombre para el nuevo esquema en el cuadro Nombre de esquema.
- En el cuadro Propietario del esquema, escriba el nombre del usuario o función de base de datos que va a poseer el esquema.
- Haga clic en Aceptar.
Para crear un esquema con Transact-SQL
- En el Editor de consultas, conéctese a la base de datos en la que se va a crear el esquema de la base de datos; para ello, ejecute el siguiente comando de Transact-SQL:
USE <database name> GO - Cree el usuario ejecutando el siguiente comando de Transact-SQL:
CREATE SCHEMA <new schema name> AUTHORIZATION [new schema owner] ;
GO
jueves, 19 de marzo de 2020
Tablas temporales en el sql server
Las Tablas versionadas o temporales se introdujeron en el estándar ANSI SQL 2011 y en SQL Server 2016 y es un tema a evaluar en la certificación de Microsoft para Consultas con SQL Server.
Una tabla versionada del sistema le permite consultar los datos actualizados y eliminados, mientras que una tabla normal sólo puede devolver los datos actuales. Por ejemplo, si se actualiza un valor de columna del 5 al 10, sólo se puede recuperar el valor 10 en una table normal. Una tabla versionada también le permite recuperar el valor anterior 5. Esto se logra
manteniendo una tabla de historial. Esta tabla almacena los datos de la historia antigua, junto con un conjunto de datos de inicio y fin para indicar cuando el registro fue activo.
manteniendo una tabla de historial. Esta tabla almacena los datos de la historia antigua, junto con un conjunto de datos de inicio y fin para indicar cuando el registro fue activo.

Estos son los casos de uso más comunes
para las tablas temporales:
para las tablas temporales:
- Auditoría. Con tablas temporales puede averiguar qué valores una entidad específica ha tenido en toda su vida.
- Cambio de dimensiones lentas en un Data Warehouse. Una tabla versionada del sistema se comporta exactamente como una dimensión de tipo 2 cambiando comportamientos de sus propias tablas En este caso, la tabla de dimensión incluye los campos de fecha inicio de vigencia y fecha fin de vigencia. Estas fechas nos permiten determinar en qué estado estaba la dimensión en cualquier fecha del calendario.
- Reparación de corrupciones a nivel de registro. Que sería como una especie de mecanismo de copia de seguridad en una sola tabla.
- Eliminación accidental de un registro. Recuperar el archivo de la tabla historial e insertarla de nuevo en la tabla principal.
Creación de una tabla versionada del sistema
Cuando se desea crear una nueva tabla
temporal, un par de pre–requisitos se deben cumplir:
temporal, un par de pre–requisitos se deben cumplir:
- Se debe definir una clave principal
- Dos columnas deben ser definidos para registrar la fecha de inicio y final con un tipo de datos de datetime2. Si es necesario, estas columnas se pueden ocultar mediante el indicador oculto.
Estas columnas se llaman las columnas de tiempo SYSTEM_TIME. - Los triggers INSTEAD OF no están permitidos. Los triggers AFTER sólo están permitidos en la tabla actual.
- Dentro de la memoria OLTP no se puede utilizar
También hay algunas limitaciones:
- tabla temporal y la historia no puede ser FileTable
- La tabla de la historia no puede tener ninguna restricción
- INSERT y UPDATE no pueden hacer referencia a las columnas de época SYSTEM_TIME
- Los datos de la tabla de historia no pueden ser modificados
La siguiente secuencia de comandos crea
una sencilla tabla versionada sistema:
una sencilla tabla versionada sistema:
CREATE TABLE dbo.TestTemporal
(ID int primary key, Multiplicando int, Multiplicador int
,Resultado AS A * B
,SysStartTime datetime2 GENERATED ALWAYS AS ROW START NOT NULL
,SysEndTime datetime2 GENERATED ALWAYS AS ROW END NOT NULL
,PERIOD FOR SYSTEM_TIME (SysStartTime,SysEndTime)) WITH(SYSTEM_VERSIONING = ON);
(ID int primary key, Multiplicando int, Multiplicador int
,Resultado AS A * B
,SysStartTime datetime2 GENERATED ALWAYS AS ROW START NOT NULL
,SysEndTime datetime2 GENERATED ALWAYS AS ROW END NOT NULL
,PERIOD FOR SYSTEM_TIME (SysStartTime,SysEndTime)) WITH(SYSTEM_VERSIONING = ON);
Si no se especifica un nombre para la tabla de historial, SQL Server
generará automáticamente una de la siguiente estructura: dbo.MSSQL_TemporalHistoryFor_,
donde <XXX> es el identificador de objeto de la tabla principal.
generará automáticamente una de la siguiente estructura: dbo.MSSQL_TemporalHistoryFor_,
donde <XXX> es el identificador de objeto de la tabla principal.
El resultado es el siguiente:

La tabla de historial tiene un conjunto idéntico de columnas, pero sin restricciones. También tiene su propio conjunto de índices y estadísticas.
Creación de sus propios índices como el índice de almacén de columnas agrupado en la tabla de historial puede mejorar considerablemente el rendimiento. Vamos a probar la funcionalidad de la tabla temporal mediante la inserción de datos en la tabla y luego modificarlo.
Creación de sus propios índices como el índice de almacén de columnas agrupado en la tabla de historial puede mejorar considerablemente el rendimiento. Vamos a probar la funcionalidad de la tabla temporal mediante la inserción de datos en la tabla y luego modificarlo.
-- Carga Inicial INSERT INTO dbo.TestTemporal (ID, A, B) VALORES (1,2,3) , (2,4,5) , (3,0,1); GO SELECT * FROM dbo.TestTemporal;

Ahora vamos a eliminar una fila y actualizar otro.
--Modificar datos
DELETE FROM dbo.TestTemporal WHERE id = 2;
UPDATE dbo.TestTemporal SET A = 5 WHERE id = 3;
GO
DELETE FROM dbo.TestTemporal WHERE id = 2;
UPDATE dbo.TestTemporal SET A = 5 WHERE id = 3;
GO
La tabla principal muestra el estado actual de los datos:

Tenga en cuenta que la columna de la SysEndTime no es necesario, ya que sólo muestra el valor máximo datetime2.
La historia muestra las versiones antiguas de las diferentes filas y están fechados correctamente.

Modificar el Esquema de una
tabla versionada
Cuando el control de versiones está
habilitado en una tabla, las modificaciones sobre la tabla son muy limitadas,
solo se permiten:
habilitado en una tabla, las modificaciones sobre la tabla son muy limitadas,
solo se permiten:
- ALTER TABLE …
REBUILD - CREATE INDEX
- CREATE STATISTICS
Todas las demás modificaciones del
esquema no están permitidas. Por ejemplo, no es posible eliminar una tabla temporal.
esquema no están permitidas. Por ejemplo, no es posible eliminar una tabla temporal.

Tampoco estaría permitido agregar una nueva columna, con el fin de alterar
el esquema de una tabla temporal, el control de versiones Se debe desactivar
primero:
el esquema de una tabla temporal, el control de versiones Se debe desactivar
primero:
ALTER TABLE dbo.TestTemporal SET
(SYSTEM_VERSIONING = OFF);
(SYSTEM_VERSIONING = OFF);
Este comando eliminará el system_versioning y convertirá la
tabla principal y la tabla de la historia en dos tablas regulares.
tabla principal y la tabla de la historia en dos tablas regulares.

Con esto se puede hacer cualquier
modificación que desee en ambas tablas. Asegúrese que los datos permanezcan
sincronizados y la historia siga siendo consistente. Después de las modificaciones, puede
activar el sistema de control de versiones de nuevo.
modificación que desee en ambas tablas. Asegúrese que los datos permanezcan
sincronizados y la historia siga siendo consistente. Después de las modificaciones, puede
activar el sistema de control de versiones de nuevo.
ALTER TABLE dbo.TestTemporal SET (SYSTEM_VERSIONING = ON (HISTORY_TABLE = dbo.TestTemporal_History, DATA_CONSISTENCY_CHECK = [ON / OFF]) );
Consultas
a Tablas Temporales
Una vez que hemos creado una tabla temporal y hemos estado modificando los
datos durante algún tiempo, por supuesto que queremos ver todos los cambios
históricos de los datos, por lo que podemos realizar consultas a la tabla.
datos durante algún tiempo, por supuesto que queremos ver todos los cambios
históricos de los datos, por lo que podemos realizar consultas a la tabla.
La siguiente secuencia de comandos creará dos tablas e insertar datos en
ella.
ella.
-- Crear tabla de historia
CREAR TABLA dbo.PriceHistory
(ID INT NOT NULL
, Producto VARCHAR (50) NOT NULL
, Precio DECIMAL(10,2) NOT NULL
, StartDate DATETIME2 NOT NULL
, EndDate DATETIME2 NOT NULL
);
GO
(ID INT NOT NULL
, Producto VARCHAR (50) NOT NULL
, Precio DECIMAL(10,2) NOT NULL
, StartDate DATETIME2 NOT NULL
, EndDate DATETIME2 NOT NULL
);
GO
— los valores de inserción para la historia
INSERT INTO dbo.PriceHistory (ID, Producto, Precio, StartDate, EndDate) VALUES
(1, ‘Myproduct’, 1.15, ’01/07/2015 00:00:00′, ’07/01/2019 11:58:00′)
, (1, ‘Myproduct’, 1.16, ’07/01/2015 11:58:00′, ’03/07/2019 12:00:00)
, (1, ‘Myproduct’, 1.18, ’07/03/2015 12:00:00′, ’05/07/2019 18:05:00)
, (1, ‘Myproduct’, 1.21, ’05/07/2015 18:05:00′, ’07/07/2019 08:33:00′);
(1, ‘Myproduct’, 1.15, ’01/07/2015 00:00:00′, ’07/01/2019 11:58:00′)
, (1, ‘Myproduct’, 1.16, ’07/01/2015 11:58:00′, ’03/07/2019 12:00:00)
, (1, ‘Myproduct’, 1.18, ’07/03/2015 12:00:00′, ’05/07/2019 18:05:00)
, (1, ‘Myproduct’, 1.21, ’05/07/2015 18:05:00′, ’07/07/2019 08:33:00′);
-- Crear tabla actual para almacenar los precios
CREAR TABLA dbo.Price
(ID INT NOT NULL
, Producto VARCHAR (50) NOT NULL
, Precio DECIMAL (10,2) NOT NULL
, StartDate DATETIME2 NOT NULL
, EndDate DATETIME2 NOT NULL
, CONSTRAINT PK_Price PRIMARY KEY CLUSTERED ( ID ASC)
);
GO
(ID INT NOT NULL
, Producto VARCHAR (50) NOT NULL
, Precio DECIMAL (10,2) NOT NULL
, StartDate DATETIME2 NOT NULL
, EndDate DATETIME2 NOT NULL
, CONSTRAINT PK_Price PRIMARY KEY CLUSTERED ( ID ASC)
);
GO
— Insertar el precio actual ¡asegúrese de que la fecha de inicio no está en el futuro!
INSERT INTO dbo.Price (ID, Producto, Precio, StartDate, EndDate)
VALUES (1, ‘MyProduct’, 1,20, ’07/07/2015 08:33:00′, ‘9999–12–31 23: 59: 59.9999999’);
VALUES (1, ‘MyProduct’, 1,20, ’07/07/2015 08:33:00′, ‘9999–12–31 23: 59: 59.9999999’);
La secuencia de comandos sólo crea filas para un producto, con el fin de
mantener el ejemplo sencillo y fácil de entender. Este producto tendrá 4
versiones históricas y 1 versión actual.
mantener el ejemplo sencillo y fácil de entender. Este producto tendrá 4
versiones históricas y 1 versión actual.

Esto se traducirá directamente en 4 filas en la tabla de historial y 1 fila
de la tabla principal. Ahora vamos a convertir esas dos tablas en una tabla
temporal.
de la tabla principal. Ahora vamos a convertir esas dos tablas en una tabla
temporal.
-- Permitir a las columnas de tiempo sistema
ALTER TABLE dbo.Price
ADD PERIOD FOR SYSTEM_TIME(StartDate, EndDate);
ADD PERIOD FOR SYSTEM_TIME(StartDate, EndDate);
-- Activar el sistema de control de versiones
ALTER TABLE dbo.Price SET (SYSTEM_VERSIONING = ON
(HISTORY_TABLE = dbo.PriceHistory, DATA_CONSISTENCY_CHECK = ON)
);
(HISTORY_TABLE = dbo.PriceHistory, DATA_CONSISTENCY_CHECK = ON)
);

SQL Server 2016 consulta Tablas temporales
La cláusula SELECT … FROM tiene una nueva cláusula en SQL Server 2016 que
es FOR SYSTEM_TIME, esta nueva cláusula
también cuenta con 5 nuevos sub-cláusulas temporales específicas. En las
siguientes secciones vamos a discutir cada uno con un ejemplo.
es FOR SYSTEM_TIME, esta nueva cláusula
también cuenta con 5 nuevos sub-cláusulas temporales específicas. En las
siguientes secciones vamos a discutir cada uno con un ejemplo.
Para llevar a cabo cualquier tipo de análisis basado en tiempo, use la
nueva cláusula FOR SYSTEM_TIME con cinco sub-cláusulas temporales específicas
para consultar datos en las tablas actuales y de historial.
nueva cláusula FOR SYSTEM_TIME con cinco sub-cláusulas temporales específicas
para consultar datos en las tablas actuales y de historial.
- AS OF
- FROM
TO - BETWEEN
AND - CONTAINED IN
( , ) - ALL
AS OF
Utilizando el AS OF de la Sub-cláusula, recupera la versión para cada fila
que era válida en ese punto específico en el tiempo. Básicamente se le permite
viajar en el tiempo a un punto determinado en el pasado para ver en qué estado
está la tabla estaba en ese punto.
que era válida en ese punto específico en el tiempo. Básicamente se le permite
viajar en el tiempo a un punto determinado en el pasado para ver en qué estado
está la tabla estaba en ese punto.
Por ejemplo:
SELECT * FROM dbo.Price FOR AS SYSTEM_TIME AS OF ‘7/4/2015’;
Esta consulta será recuperar la versión que estaba en vigor el 4 de julio
(medianoche).
(medianoche).

La tercera versión será devuelta, que tiene el precio de 1,18.

Tenga en cuenta que no es necesario conocer el nombre de la tabla de
historia o cómo se construye la tabla temporal. El uso de la tabla temporal es
transparente: sólo tiene que consultar la tabla mediante la cláusula FOR
SYSTEM_TIME y SQL Server controla todo el resto. Al mirar el plan de ejecución
real, se puede ver uniones de SQL Server de la tabla principal y la tabla de
historia junta y filtros para las filas solicitadas.
historia o cómo se construye la tabla temporal. El uso de la tabla temporal es
transparente: sólo tiene que consultar la tabla mediante la cláusula FOR
SYSTEM_TIME y SQL Server controla todo el resto. Al mirar el plan de ejecución
real, se puede ver uniones de SQL Server de la tabla principal y la tabla de
historia junta y filtros para las filas solicitadas.

¿Qué pasa con el caso en el que el borde AL punto en el tiempo cae en un
límite? En otras palabras, el punto en el tiempo es igual a la fecha de
finalización de una versión y la fecha de inicio de la versión que viene justo
después. Vamos a probarlo.
límite? En otras palabras, el punto en el tiempo es igual a la fecha de
finalización de una versión y la fecha de inicio de la versión que viene justo
después. Vamos a probarlo.
SELECT * FROM dbo.Price
FOR SYSTEM_TIME AS OF ’07/03/2015 12:00:00′;
FOR SYSTEM_TIME AS OF ’07/03/2015 12:00:00′;
Esto devolverá la versión más reciente:

Consulta de A a B de la tabla temporal de datos de SQL
Server
Server
Esta cláusula es funcionalmente equivalente a la construcción siguiente:
StartDate A
se devolverán todas las filas históricas y actuales que estaban en algún
momento activo en el período de tiempo entre A y B. toda la vida de un registro
de este tipo puede ser más grande que el período de tiempo entre A y B.
momento activo en el período de tiempo entre A y B. toda la vida de un registro
de este tipo puede ser más grande que el período de tiempo entre A y B.
Por ejemplo:
SELECT * FROM dbo.Price
FOR SYSTEM_TIME FROM ‘7/2/2015’ A ‘7/6/2015’;
FOR SYSTEM_TIME FROM ‘7/2/2015’ A ‘7/6/2015’;
Esta consulta devolverá todas las versiones que estaban en algún momento
activo en el período de tiempo entre el 2 de julio y el 6 de julio.
activo en el período de tiempo entre el 2 de julio y el 6 de julio.

Versión 2, 3 y 4 serán devueltos.

Lo que si A
y B son los mismos puntos en el tiempo?
y B son los mismos puntos en el tiempo?
SELECT * FROM dbo.Price
FOR SYSTEM_TIME FROM ‘7/6/2015’ A ‘7/6/2015’;
FOR SYSTEM_TIME FROM ‘7/6/2015’ A ‘7/6/2015’;
Este será el mismo que se utiliza AS DE. se devolverán las versiones
válidas en ese punto específico en el tiempo:
válidas en ese punto específico en el tiempo:

Sin embargo, el comportamiento difiere de AL cuando el punto en el tiempo
es en un límite de dos versiones.
es en un límite de dos versiones.
SELECT * FROM dbo.Price
FORM SYSTEM_TIME FROM ’07/03/2015 12:00:00′ A ’03/07/2015 12:00:00′;
FORM SYSTEM_TIME FROM ’07/03/2015 12:00:00′ A ’03/07/2015 12:00:00′;
En este caso, no hay registros no se devuelven!

Entre A y B lógica para las tablas de SQL Server
temporales
temporales
Esta sub-cláusula es funcionalmente equivalente a la construcción
siguiente:
siguiente:
StartDate ≤ B AND EndDate > A
En la mayoría de los casos esto también es equivalente a la de A a B, excepto cuando la fecha de finalización del período de tiempo (B) cae en un límite. Con entre A y B, se incluía esta frontera. Vamos a echar un vistazo al mismo ejemplo que en la sección anterior, pero con el rango ampliado hasta el punto de partida de la versión actual. En el ejemplo he comparado el medio y la DE A subcláusula.

La diferencia entre las dos cláusulas es ahora muy claro: entre A y B incluye el límite superior del marco de tiempo, lo que se traduce en una versión extra que se devuelve. Cuando A y B son los mismos, entre A y B es el equivalente de AL.
Aunque es similar al operador BETWEEN utilizado en la cláusula WHERE, hay una diferencia sutil ya que el operador BETWEEN incluye ambos límites, mientras que el temporal entre la sub–cláusula sólo se incluye el límite inferior.
CONTENIDO EN lógica (A, B) para las tablas de SQL
Server temporal
Server temporal
El último sub-cláusula tiene la siguiente equivalente funcional:
Un StartDate ≤ Y ≤ B EndDate
Sólo se volverá versiones de los cuales el intervalo de tiempo válido es totalmente dentro del rango de tiempo especificado, límites incluidos. Una vez que una versión cruza el límite del intervalo de tiempo, se incluye. Utilizamos el mismo ejemplo que en las secciones anteriores.

SELECT * FROM dbo.Price
FOR SYSTEM_TIME CONTAINED IN ( ‘2/7/2015′, ’07/06/2015’);
FOR SYSTEM_TIME CONTAINED IN ( ‘2/7/2015′, ’07/06/2015’);
La consulta ahora sólo volverá versión 3, ya que es la única versión
completamente dentro del punto medio del rango de inicio y fin. La versión 2 y
la versión 4 cruzan las fronteras, por lo que se excluyen.
completamente dentro del punto medio del rango de inicio y fin. La versión 2 y
la versión 4 cruzan las fronteras, por lo que se excluyen.

Tener A y B de la misma sería bastante inútil, ya que una consulta de este
tipo sólo volvería versiones que tenían una vida de exactamente un punto en el
tiempo.
Suscribirse a:
Entradas (Atom)